Health Checks - CUCM - CallManager
𝄞 This Is How We Do It 𝄞
And here it is, my list of commands and checks that I run against CUCM nodes (7.x-12.x) for most changes that take place. It’s useful output to collect prior to changing configurations like domains, DNS servers, IP/Hostname changes, Upgrades, Restarts – anything that makes a change system wide.
I pull this data to refer back to in the event that the change has disrupted dbrepliction, endpoint registration status, inter-cluster communication, intra-cluster communication, service status, anything. Consider this output a “CYA” for later. Something to refer back to to confirm all is as it was prior to the change, with whatever exceptions should exist (e.g. IP address changed should reflect in post-change “show network eth0 detail” output.
So without further adieu, this is my personal list:
Health Check Commands [CUCM]
show status
Shows the status of the system, such as system uptime, disk I/O usage, CPU usage, Memory usage, Partition space, Platform version and more.
show version active
Shows the version installed into the active partition as well as any cop files installed.
show version inactive
Shows the version installed into the inactive partition as well as any cop files installed.
show hardware
Shows data relating to the underlying hardware of the system, less pertinent for virtualized servers. In the case of virtualization we would refer to additional ESXi and UCS-C/B/E command output for hardware status.
show network cluster
Returns a list of IP addresses and hostnames/FQDNs for CUC nodes joined to the cluster.
show perf query class Processor|Memory
Query perfmon to review data relating to memory, virtual memory, swap, CPU usage/allocation.
utils diagnose test
Runs self diagnostics on the CUC node itself pertaining to disk, memory, tomcat, DNS, NTP and other functions. Can detect various issues, such as the ever-common “reverse dns lookup failure” and more.
utils service list
| Returns the list of services running on the CUC node, whether it is the Publisher node or not, and what the state of the service is (running | notrunning). |
utils ntp status
Reports back the status of configured NTP servers, what the stratum is currently, and the jitter, and latency is to each.
utils disaster_recovery history backup
Reports back the last 10 (or so) backups, whether they succeeded or failed, what components were backed up and on what date. Also displays what the network device was that was used for SFTP backup.
utils dbreplication runtimestate
Reports back the state of dbreplication AS PER THE LAST STATUS CHECK. This includes the dbreplication state (should be 2), what the replication queue looks like, as well as what nodes are participating in replication.
Replication should be confirmed as ‘healthy’ prior to completing any work. Resolve any replication issues before performing upgrades or other work. To run a fresh status check of dbreplication, issue the command utils dbreplication status
utils core active list
Provides a list of all core files found. Core files are generated whenever a service crashes. These should be analyzed and the backtrace analyzed against open Cisco Bug IDs, or by Cisco TAC.
*To analyze the backtrace of a core file, issue utils core active analyze
show risdb query misc phone phonefailed cmnode cmgroup cti ctiextn uone huntlist ctimlist gateway sip mediaresource h323
Pulls the RIS Database data for the related entries. Assists in confirming all endpoints, such as media resources, h323 devices, MGCP gateways, SIP Trunks, Hunt Lists and more register. Allows us to check the registration state pre and post change.
Screenshots
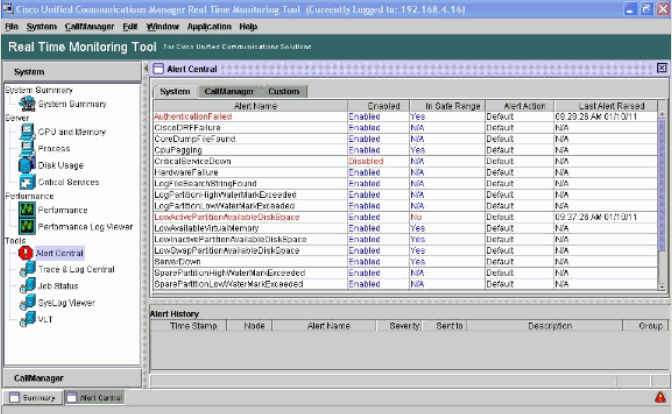
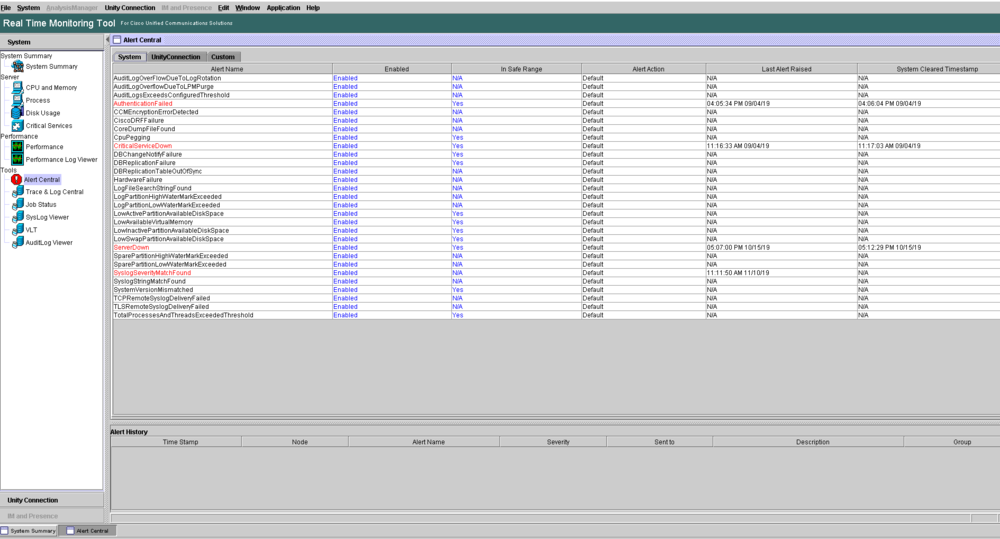
Alert Central - RTMT
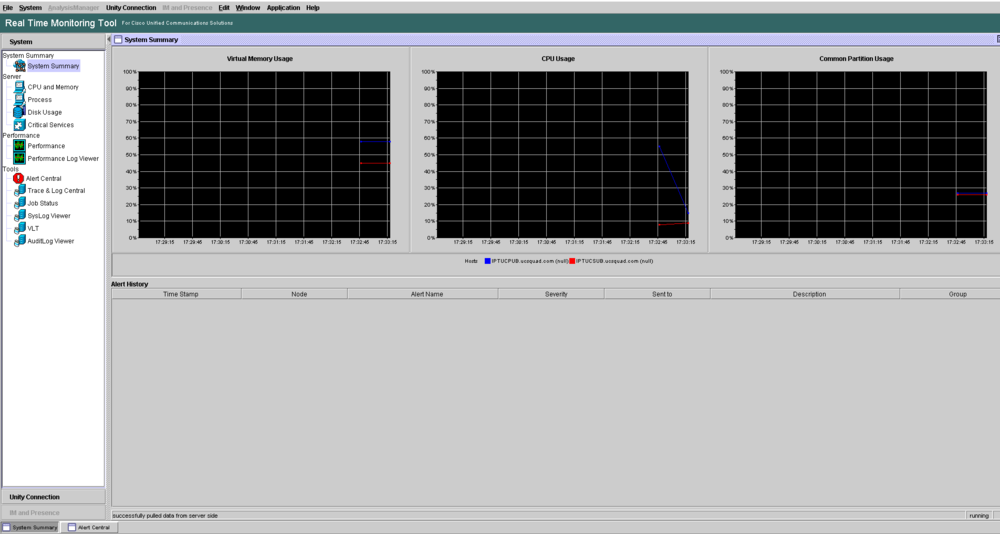
System Summary - RTMT
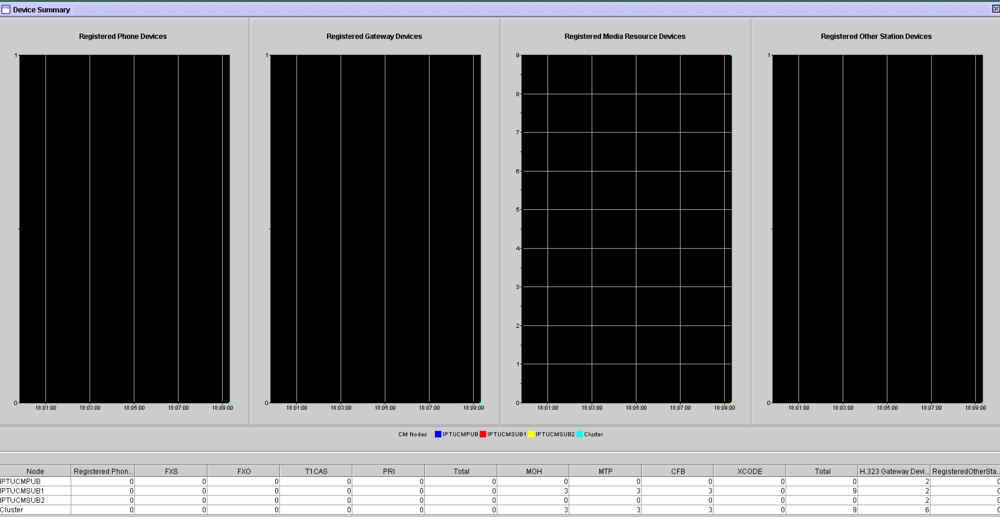
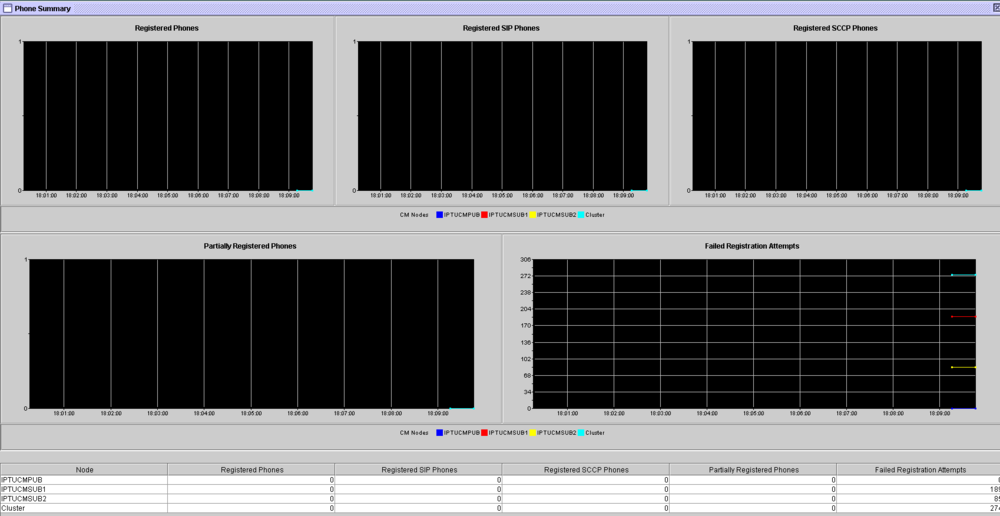
Registered Phones/Devices (Cluster) - RTMT
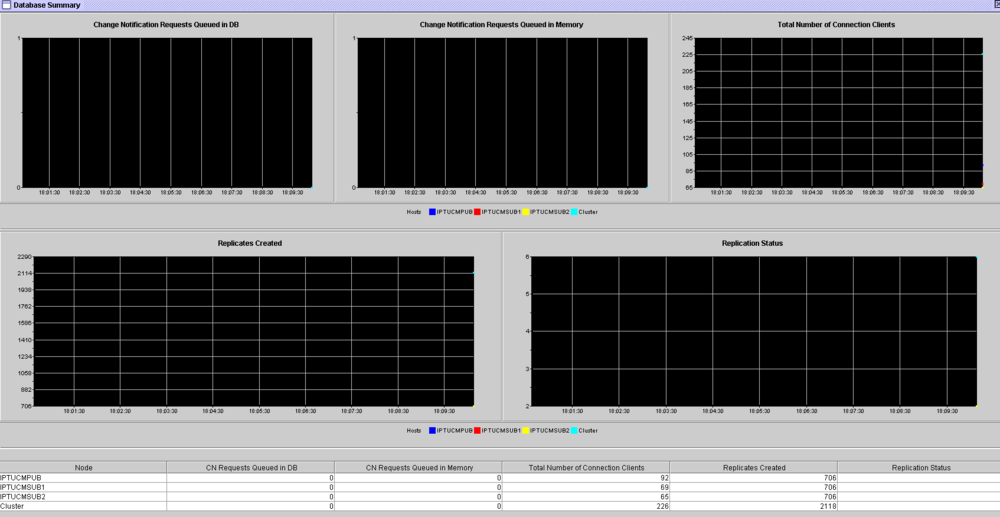
Database Summary - RTMT
For health checks, I don’t download Reports from the Cisco Unified Reporting feature, as it does not contain data that I’d want to refer to for verification. They are however helpful, at times, in troubleshooting issues on the system and getting deeper insights into database replication/setup, for example.
And I typically don’t just want to trust the CUCM node alone, I also want to refer to RTMT and endpoint [IOS/IOS-XE/CUC/EXPRESSWAY/etc] output for devices that are associated with the change and may be indirectly impacted. Those devices are not covered here, please refer to the relevant health check post for commands to review from the far end.
So what do you look for when you perform scheduled work? Are you the run-and-gun type that just performs the changes and shrugs at health checks (heathen!) or do you verify against your own personal check list of commands? I’d love to hear it! Think I forgot something important? Let me know! We can all benefit from getting in the habit of defining and following better practices and documentation strategies!
That’s it for now! Make sure to follow the blog to get alerts on new posts, check out my Twitter (@kperryuc) where you can also ask UC and DC related questions, suggest post topics, or talk about anything! You can also join our Discord!